
AI大模型的训练阶段通常被认为是能源消耗最高的阶段。在此阶段,训练诸如GPT系列的大模型需要大量的数据集进行训练,并通过调整其参数来使预测输出与目标输出尽可能一致。
虽然大模型训练阶段的能耗很高,但有证据表明,大模型推理调用频率远高于训练,导致推理阶段的能耗可能更高,成为更大的“电老虎”。
大模型推理能耗更高
随着大模型的快速发展,与之相关的能源消耗也在快速增长。在训练阶段,大模型就是“电老虎”。
Hugging Face曾透露其BLOOM 大模型在训练期间消耗了433兆瓦时(MWh)的电力。而其他大模型,如GPT-3、Gopher和OPT,在训练期间分别消耗了1287、1066和324 MWh的电力。这些模型都在TB级别的数据上进行训练,并具有1750亿个或更多参数。
这些能源消耗的数据看起来确实很惊人,但是大模型训练通常只需要几个月的时间,只有集中训练期间对能源的消耗比较大。一旦模型训练完毕,则会进入部署应用阶段,也就所谓的推理阶段。
然而研究表明,推理阶段,即模型在实际应用中生成输出(例如,ChatGPT的回复用户查询),也可能消耗大量的能源,甚至可能高于训练阶段。
2023年2月,半导体分析机构SemiAnalysis曾估计,OpenAI需要3617台NVIDIA的HGX A100服务器(共28936个GPU)来支持ChatGPT,这意味着每天的能耗为564 MWh,用于处理约2亿个用户请求。相比GPT-3训练阶段估计使用的1287 MWh,推理阶段的能源需求明显要高得多。
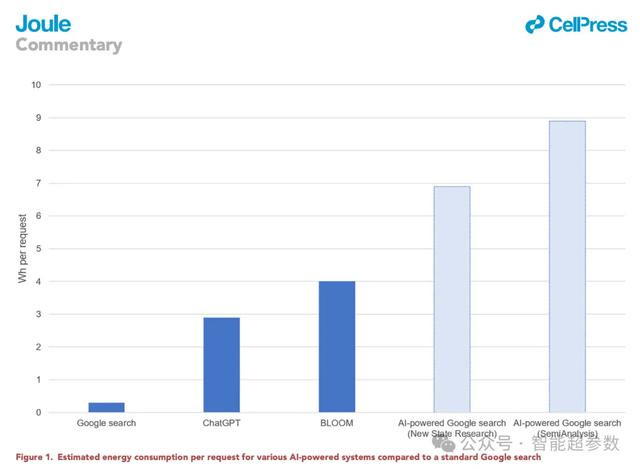
SemiAnalysis同样预估,如果将类似ChatGPT的AI整合到每一次谷歌搜索中,可能需要512,821台NVIDIA的HGX A100服务器,如果按照每台服务6.5 kW 功率计算,每天能耗要达到80 GWh,年能源消耗量达到 29.2 TWh。
这些预估数据表明,这种谷歌搜索全面转向AI搜索,可能会使谷歌年用电量增加到与整个爱尔兰的用电量相当。
大模型推理过程中能源消耗影响因素
现在,这些大模型开始在各个领域广泛应用,一个日益紧迫的问题也浮出水面:这些大模型在实际推理过程中需要消耗多少能源?其能源成本是否可持续?
最近,麻省理工学院(MIT)等机构的研究人员进行了一项深入的研究,旨在量化分析大语言模型推理的能源成本。
研究以Meta AI的LLaMA模型为对象,在不同的硬件(NVIDIA V100和A100 GPU)和数据集(Alpaca和GSM8K)上进行了实验。
研究评估了不同大小的LLaMA模型(7B,13B和65B)在最低硬件配置下的推理性能和能耗。此外,还深入分析了LLaMA 65B模型在多GPU和多节点环境下的分布式推理性能,以及不同的批处理大小和分片数量对能源消耗的影响。研究的评估指标包括:每秒字数、每秒token数、每秒响应数、GPU利用率、能源消耗(焦耳),以及每秒能源消耗(瓦特)、每个token能源消耗和每个响应能源消耗。
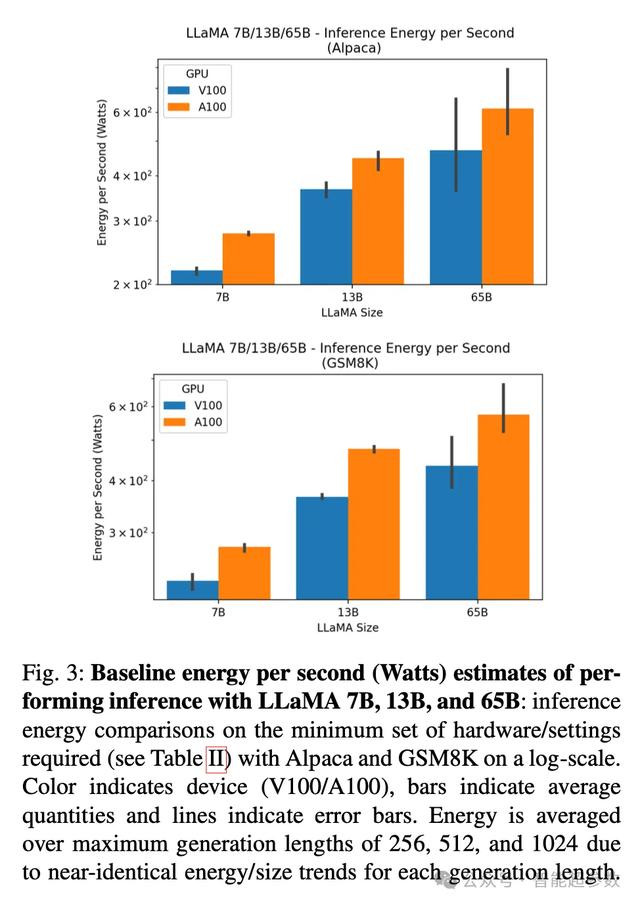
研究发现,A100 GPU 在推理性能上明显优于 V100 GPU,尤其是在较小的 LLaMA 模型(7B 和 13B)上,推理速度提升了 1.25 到 2 倍。但在相同的模型大小下,使用 A100 GPU 的能耗也显著增加,尤其是在 LLaMA 7B 模型上。因此,推理阶段,选择GPU类型需要权衡性能和能耗。
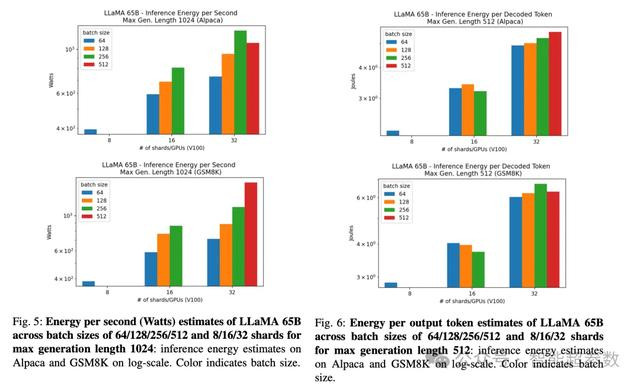
同时,就像汽车排量越大越耗油一样,模型越大推理也越“耗电”。研究发现,对于 LLaMA 65B 这样的大模型,通常需要进行分布式推理,但是随着分片数量的增加,推理的能耗也随之增加。
那么如何才能降低大模型的能耗呢?
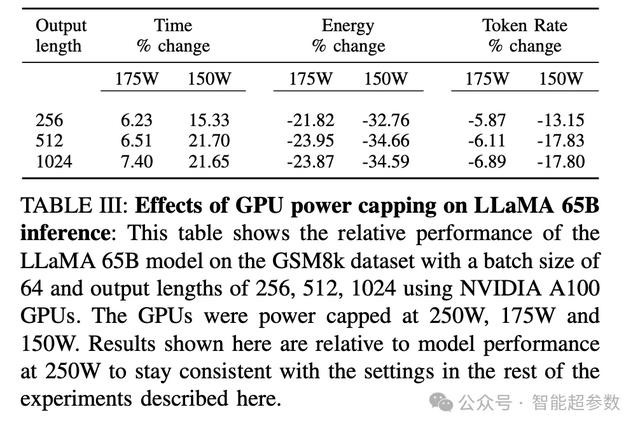
研究人员测试了GPU功耗限制(power capping)对LLaMA 65B模型推理时间、能耗和token生成速率的影响。研究发现,通过降低GPU的功耗上限,可以大幅度减少推理过程中的能源消耗,但这可能会导致推理时间的略微增加。
例如,研究团队将功耗限制从250W降至175W,可以实现平均23.21%的能耗降低,同时推理时间仅平均增加约6.7%。而如果大幅度降低功耗限制,例如从250W降至150W,推理时间则显著增加,平均增幅约 19.49%。
最新研究具有较强的实际意义。在实际部署大模型时,数据中心可以根据不同的工作负载和性能需求,动态调整GPU类型以及控制功耗上限,从而降低运营成本和环境影响。